Summary
TeleCloud’s service team needed a more consistent way to review completed tickets without turning team leads into full-time quality-control reviewers. The existing QC process depended on experienced people reading tickets, questioning technicians when details were missing, and re-reviewing the work after updates. Done properly, that could take 4-6 minutes per ticket from someone making roughly $80,000 a year. In practice, the work often became inconsistent because the team had more urgent things to handle.
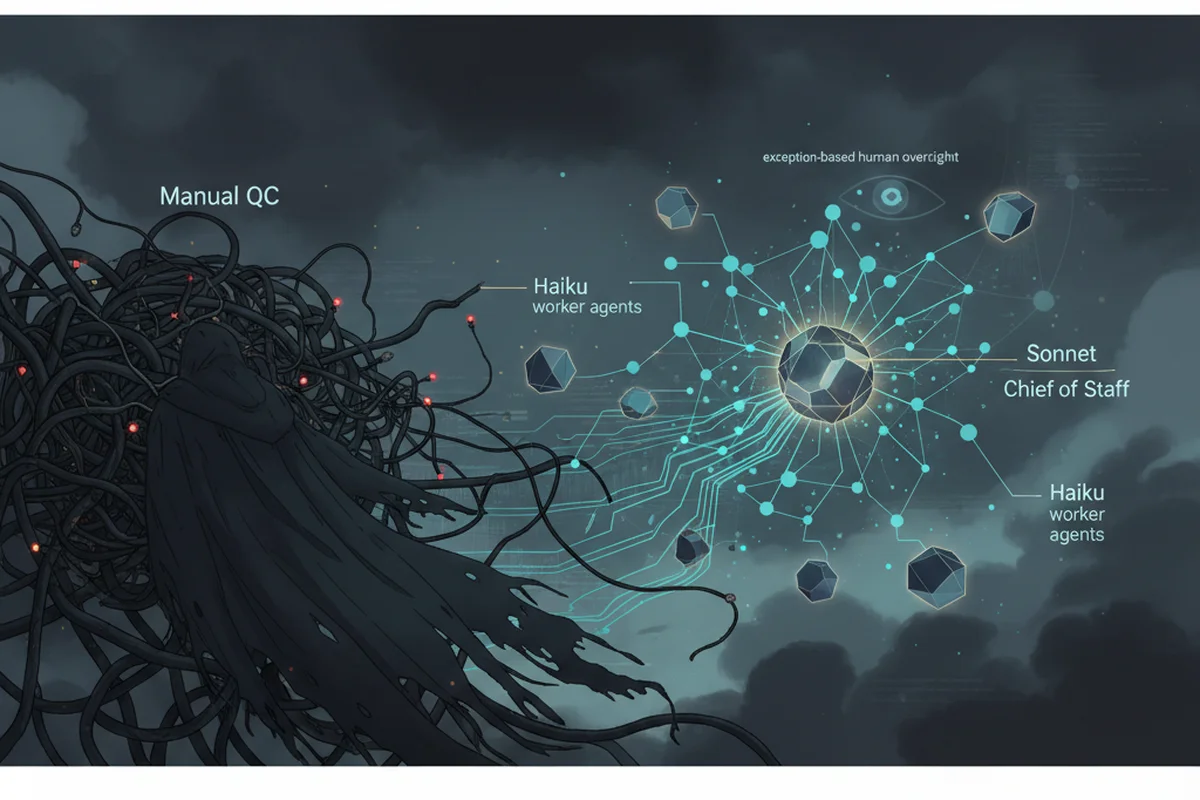
I built an agentic observability platform for internal operations. The system uses structured agents to review tickets, post summaries, flag failures, and write observations into a shared dashboard. A stronger Chief of Staff agent watches the system for repeated patterns and decides when an agent needs better context, rewritten prompts, or new escalation rules.
The result is a shift from manual ticket-by-ticket QC to exception-based review. In one production run, the system processed 62 tickets for $0.74. Human oversight is now mostly limited to checking failures in the observability portal, which takes less than an hour per week.
The Challenge
Ticket QC is easy to underestimate. A good ticket needs to explain the customer’s issue, the work requested, the work performed, the root cause, and any follow-up. That information matters later when another technician reopens the account, a customer asks what happened, or a manager needs to coach the team.
The manual process was straightforward but expensive in attention. A team lead would spend 2-3 minutes reading through a completed ticket and sending questions back to the technician if anything was missing. After the technician responded, the lead would spend another 2-3 minutes re-reviewing the ticket. That made the real QC cycle 4-6 minutes per ticket.
The larger problem was consistency. If QC was done well, it consumed leadership time. If the team got busy, QC became informal or skipped. Tickets also were not consistently getting clean summaries, which made future review harder than it needed to be.
The Approach
The first step was to turn tribal judgment into documented standards. I used Claude Cowork to analyze 5,000 historical tickets and identify the patterns behind good and bad ticket documentation. The team already knew the general standard, but an agent needs that standard written down clearly enough to apply it repeatedly.
That analysis became four context files: a QC rubric, escalation rules, known ticket patterns, and QC standards. The rubric defines how each ticket should be reviewed. The escalation rules define what the agent should not handle on its own. The known patterns file captures recurring issues from historical tickets. The standards file explains what “good” looks like in our environment.
Once the review process was documented, the model requirements changed. I originally assumed the QC work would need Sonnet because the task felt nuanced. After testing, Haiku produced nearly identical results for the structured review work. That became the model routing pattern: cheaper models handle repeatable work with clear standards, while stronger models handle orchestration, pattern recognition, and system improvement.
Architecture
The platform has four main pieces: a triage agent, a QC agent, an observability portal, and a Chief of Staff agent. The triage agent helps gather and structure ticket information before QC. The QC agent reviews completed tickets against the documented standard and posts a clear summary. The observability portal shows agent activity, failures, weak tickets, and recurring patterns. The Chief of Staff agent watches the system across agents and decides when repeated failures need a prompt change, context rewrite, or escalation rule.
The important part is the feedback loop. If the QC agent repeatedly reports that the triage agent did not gather enough detail, that does not stay buried in a ticket. The observation is visible in the portal. If it happens repeatedly, the Chief of Staff agent reviews the pattern and recommends a system-level fix.
Workflow
Before the platform, a technician completed a ticket and a service lead reviewed it if they had time. If details were missing, the lead sent questions back, waited for the technician to respond, and then re-reviewed the ticket. The process depended on human follow-through at every step.
Now the QC agent reviews the ticket against the rubric, posts a summary, and flags weak or incomplete work. Humans review the exceptions in the observability portal instead of reading every ticket manually. The Chief of Staff agent watches for repeated issues across the agents and identifies when the system itself needs to improve.
This changed the human role from first-pass reviewer to exception reviewer.
Results
The system processed 62 tickets through QC for $0.74. Manual QC would have required 4-6 minutes per ticket from an employee around an $80,000 salary level, assuming the process happened correctly every time.
The bigger win is operational consistency. Ticket summaries now happen automatically. Failures are visible. Repeated problems can be addressed at the system level instead of corrected one ticket at a time. Human review is down to checking the observability portal for failures, which takes less than an hour per week.
Trade-offs
This only works because the standards were documented first. Haiku can apply a rubric, but it should not invent the rubric. The upfront work, analyzing historical tickets, writing context files, defining escalation rules, and building observability, is what makes the cheaper model useful.
The system also needs maintenance. Context files need to improve as new patterns appear. Failure modes need to be watched. The Chief of Staff agent helps with that, but the point is not to pretend agents never fail. The point is to make failures visible enough that the system can improve.
Recommendation
For internal operations, the winning pattern is not “give an agent a task and hope it works.” The better pattern is: document the standard, constrain the agent, make the work observable, review exceptions, and use a stronger model to watch for system-level patterns.
That is how smaller models become useful in production. Not because they are secretly as capable as the expensive models, but because the work around them is clear enough for them to succeed.